對比學(xué)習(xí)在CV與NLP領(lǐng)域的研究進展與技術(shù)發(fā)展
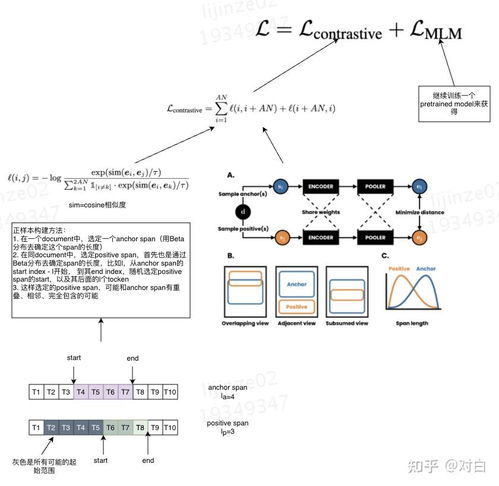
對比學(xué)習(xí)作為一種自監(jiān)督學(xué)習(xí)方法,近年來在計算機視覺和自然語言處理領(lǐng)域取得了突破性進展。它通過拉近相似樣本、推遠不相似樣本的方式學(xué)習(xí)數(shù)據(jù)的表征,顯著提升了模型在無標注或少量標注數(shù)據(jù)上的性能。
一、計算機視覺領(lǐng)域的研究進展
在CV領(lǐng)域,對比學(xué)習(xí)最初通過SimCLR、MoCo等框架展現(xiàn)了強大潛力。SimCLR通過數(shù)據(jù)增強構(gòu)建正樣本對,利用NT-Xent損失函數(shù)進行優(yōu)化;MoCo則引入動量編碼器和動態(tài)隊列,穩(wěn)定了負樣本的對比過程。BYOL和SimSiam進一步探索了無需負樣本的對比學(xué)習(xí)范式,通過預(yù)測頭架構(gòu)和停止梯度操作避免了模型坍塌問題。這些方法在ImageNet等基準數(shù)據(jù)集上取得了與監(jiān)督學(xué)習(xí)相媲美的性能,并推動了目標檢測、語義分割等下游任務(wù)的進步。近期研究聚焦于多模態(tài)對比學(xué)習(xí)(如CLIP),通過圖像-文本對訓(xùn)練實現(xiàn)零樣本泛化能力,極大拓展了應(yīng)用邊界。
二、自然語言處理領(lǐng)域的技術(shù)演進
NLP領(lǐng)域早期通過Word2Vec的Skip-gram模型隱含了對比思想,而真正突破始于SimCSE和BERT對比學(xué)習(xí)變體。SimCSE通過Dropout噪聲構(gòu)建句子級正樣本,顯著提升了語義相似度計算效果。InfoWord、DeCLUTR等工作則針對詞、句級別表征進行對比優(yōu)化。關(guān)鍵進展體現(xiàn)在:1)結(jié)合掩碼語言建模的混合預(yù)訓(xùn)練策略(如ELECTRA);2)跨模態(tài)對比學(xué)習(xí)(如VisualBERT),對齊視覺與語言表征;3)提示學(xué)習(xí)與對比結(jié)合,提升小樣本場景性能。當前,對比學(xué)習(xí)已成為提升預(yù)訓(xùn)練語言模型魯棒性和語義理解能力的重要手段。
三、核心技術(shù)創(chuàng)新與試驗發(fā)展
- 負樣本處理技術(shù):從大規(guī)模負樣本隊列(MoCo)到基于聚類的原型對比(SwAV),再到完全消除負樣本的方法,研究者不斷優(yōu)化計算效率與表征質(zhì)量平衡。
- 損失函數(shù)設(shè)計:InfoNCE損失成為主流,其溫度參數(shù)調(diào)節(jié)成為研究熱點;Triplet Loss、Circle Loss等變體針對困難樣本優(yōu)化。
- 數(shù)據(jù)增強策略:CV領(lǐng)域依賴裁剪、色彩抖動等圖像增強;NLP領(lǐng)域則探索回譯、詞替換等文本增強方法,但文本語義保持仍是挑戰(zhàn)。
- 理論突破:對比學(xué)習(xí)與互信息最大化的理論聯(lián)系被深入探討,最近的研究揭示了梯度一致性與表征坍縮的內(nèi)在機制。
- 跨領(lǐng)域融合:多模態(tài)對比框架(如ALIGN)通過數(shù)十億級圖像-文本對訓(xùn)練,實現(xiàn)了開放域理解能力的飛躍。
四、挑戰(zhàn)與未來方向
盡管成果顯著,對比學(xué)習(xí)仍面臨諸多挑戰(zhàn):1)對數(shù)據(jù)增強的高度依賴限制了領(lǐng)域適應(yīng)性;2)負樣本在高度相似場景中的判別困境;3)計算資源消耗巨大。未來趨勢可能包括:
- 輕量化對比框架設(shè)計,降低計算門檻
- 結(jié)合因果推理提升表征可解釋性
- 探索量子化對比學(xué)習(xí)等新型優(yōu)化范式
- 在醫(yī)療影像、科學(xué)文獻分析等垂直領(lǐng)域的深化應(yīng)用
對比學(xué)習(xí)通過不斷創(chuàng)新的技術(shù)路徑,正在重塑CV與NLP領(lǐng)域的表征學(xué)習(xí)范式。隨著理論體系的完善與跨學(xué)科融合的深入,其有望成為通向通用人工智能的關(guān)鍵基石之一。
如若轉(zhuǎn)載,請注明出處:http://m.xishuigroup.com.cn/product/70.html
更新時間:2026-04-07 22:46:23